Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Кодирование методом Хаффмана
Процесс кодирования поясняется табл. 5.9. Для составления кодовой комбинации, соответствующей данному знаку, необходимо проследить путь перехода знака по строкам и столбцам таблицы. Таблица 5.9
Теперь, двигаясь по кодовому дереву сверху вниз, можно записать для каждой буквы соответствующую ей кодовую комбинацию:
Известно, что при объединении зависимых систем суммарная энтропия меньше суммы энтропии отдельных систем; следовательно, информация, передаваемая отрезком связного текста, всегда меньше, чем информация на один символ, умноженная на число символов. С учетом этого обстоятельства более экономный код можно построить, если кодировать не каждую букву в отдельности, а целые «блоки» из букв. Например, в русском тексте имеет смысл кодировать целиком некоторые часто встречающиеся комбинации букв, как «тся», «ает», «ние» и т. п. Кодируемые блоки располагаются в порядке убывания частот, а двоичное кодирование осуществляется по тому же принципу. Не останавливаясь специально на методах кодирования блоками, ограничимся тем, что сформулируем относящуюся сюда теорему Шеннона. Если пропускная способность канала связи больше энтропии источника информации в единицу времени, то можно найти такой способ эффективного кодирования, который обеспечит передачу всех сообщений источника без задержки (первая теорема Шеннона).
Словарное сжатие. Словарный компрессор добивается сжатия заменой группы последовательных символов (фраз) индексами некоторого словаря. Словарь есть список таких фраз, которые, как ожидается, будут часто использоваться. Индексы устроены так, что в среднем они занимают места меньше, чем кодируемые ими фразы, за счет чего и достигается сжатие. Главное достоинство словарных методов заключается не в степени сжатия, а в экономии машинных ресурсов. Большинство практических словарных кодировщиков реализует алгоритмы, имеющие в своей основе подход, предложенный Лемпелом и Зивом (Lempel, Ziv). Сжатие Лемпела-Зива (LZ-сжатие) осуществляет преобразование блоков данных переменного размера в кодовые слова постоянной длины, когда статистика и вид фраз заранее неизвестны (адаптивное словарное кодирование).
Сущность LZ-сжатия состоит в том, что фразы сжимаемого сообщения заменяются указателями на те места, где эти фразы можно взять. Конкретизация сказанного нашла отражение в двух вариантах: 1. Кодируемые строки (фразы) заменяются указателями на строки, расположенные в скользящем окне фиксированной длины, хранящем предыдущий текст сообщения. Указатель содержит информацию о расположении строки в окне и ее длине. Этот вариант реализован в алгоритме LZ77. 2. Кодируемые строки заменяются указателями на список уже закодированных строк, хранящихся в словаре кодера. Этот вариант представлен в алгоритме LZ78. Раскодирование сжатого текста осуществляется напрямую - происходит просто замена указателя той готовой фразой, на которую он указывает. Широкое применение алгоритмов LZ-сжатия объясняется простатой реализации на современной электронной базе, высоким коэффициентом сжатия, большим разнообразием алгоритмов. Теоретически коэффициент сжатия LZ77 больше, чем LZ78, но реализуется алгоритм LZ77 медленнее. Средства, на основе которых выполняется алгоритм LZ77, асимметричны. Кодер достаточно сложен и выполняет большое количество операций. При этом основные ресурсы тратятся на поиск повторов кодируемой строки в скользящем окне просмотра. Декодер же прост в реализации и может работать с большой скоростью. Алгоритм LZ77 используется тогда, когда сообщение сжимается один раз, а восстанавливается неоднократно. Алгоритмы LZ-сжатия LZ77 - это была первая опубликованная версия LZ-сжатия. Алгоритм LZ77 в качестве модели данных использует скользящее по сообщению окно размером в N символов, разделенное на две неравные части. Первая (словарь) в (N - K символов, и большая по размеру (несколько килобайтов), включает часть (строку) уже просмотренного и закодированного сообщения. Вторая, намного меньшая, размером К символов выступает в качестве буфера и содержит еще незакодированные символы (К символов) входного потока. Обычно К имеет размер не более 100 байт.
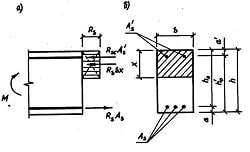
Осуществляется поиск в словаре самой длинной подстроки, совпадающей с началом (фрагментом) содержимого буфера. Найденное соответствие представляется триадой (i, j, а). В этой триаде i - смещение найденной подстроки от начала буфера, j - длина кодируемого фрагмента, а - символ буфера, расположенный на (j +1)-й позиции, т. е. первый несовпадающий символ, следующий за окончанием кодируемого фрагмента (рис. 4.6). После кодирования окно сдвигается вправо на j +1 символ, втягивая j +1 очередных символов сообщения. Если на очередном шаге совпадение не обнаружено, алгоритм выдает код (0, 0, первый символ в буфере) и продолжает свою работу. Хотя такое решение неэффективно, оно гарантирует, что алгоритм сможет закодировать любое сообщение. Недостатки алгоритма LZ77 связаны с проблемой быстродействия, обусловленной необходимостью поиска совпадающей подстроки в словаре. Вторая проблема возникает тогда, когда такого совпадения не находится, и кодер кодирует уже приведенную выше триаду. В этом случае будет иметь место не сжатие, а, наоборот, расширение, что снижает эффективность алгоритма.
Рис.4.6 Кодирование по алгоритму LZ 77
LZ78 уходит от идеи скользящего по сообщению окна. В отличие от LZ77 в LZ78 словарем является потенциально бесконечный список уже просмотренных фраз, на которые разбивается сжимаемый текст. Текст разбивается на фразы, где каждая новая фраза есть самая длинная из уже просмотренных фраз плюс один символ. Код фразы содержит номер (индекс) фразы плюс значение добавленного символа. Такая фраза присоединяется к списку фраз, на который можно ссылаться при последующем кодировании. Например, строка сссbbсbссbсссbсb, как показано на рис. 4.7, делится на семь фраз. Каждая из них кодируется как уже встречавшаяся фраза плюс, текущий символ. Например, последние три символа bсb представляются как фраза № 4 bc, за которой следует символ b. Таким образом, запись (i, а) обозначает копирование фразы i перед символом а. По мере выполнения кодирования происходит накопление фраз, т. е. увеличение словаря и необходимой для его хранения памяти. При заполнении доступной памяти она очищается, и процедура начинается как бы заново с пустым словарем.
Рис. 4.7 Кодирование по алгоритму LZ78
Сжатие с потерями.
|
||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2020-11-11; просмотров: 141; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.148.102.127 (0.007 с.) |

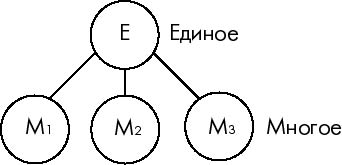
 Для наглядности строим кодовое дерево. Из точки, соответствующей вероятности 1, направляем две ветви, причем ветви с большей вероятностью присваиваем символ 1, а с меньшей 0. Такое последовательное ветвление продолжаем до тех пор, пока не дойдем до вероятности каждой буквы. Кодовое дерево для алфавита букв, рассматриваемого в табл. 5.9, приведено на рис. 5.16.
Для наглядности строим кодовое дерево. Из точки, соответствующей вероятности 1, направляем две ветви, причем ветви с большей вероятностью присваиваем символ 1, а с меньшей 0. Такое последовательное ветвление продолжаем до тех пор, пока не дойдем до вероятности каждой буквы. Кодовое дерево для алфавита букв, рассматриваемого в табл. 5.9, приведено на рис. 5.16.